
GSoC, Week 1 Progress: Tech Stack Selection and Software Architecture Diagram.


Before we dive into project details, it's important to know the background and the reasons for this project. In the next two sections, we will explore in simpler terms what this project is all about and why it needs to exist, providing insights into its purpose and significance.
What Is This Project and What Are Its Features❓
👀 Project Overview:
Our goal is to create an open-source project for locating Swagger and OpenAPI definitions on the web and other lesser-known sources called OpenAPI Web Search. In this project, we will be crawling web pages to search for API definitions, validating them, and consuming them to build an indexed search system. In more laymen's terms, The goal is fairly straightforward: I need to develop a solution that crawls for Swagger and OpenAPI definitions on the open web, common crawl, and other lesser-known sources.
The TLDR; is the solution that should function like a search engine for OpenAPI and Swagger definitions.
✨ Features:
Crawling a Large Number of Datasets
Storing the Datasets for Further Research
Validating the Resources
Providing the Search Interface
Providing the Filter Interface
Providing the functionality of Downloading API Resources
Let's start with, Why This Project Needs to Exist? 🤔
In the development domain, there is a common problem that our project aims to solve is the lack of discoverability of validated APIs faced by developers: the difficulty in finding and accessing the validated APIs, especially those from lesser-known sources on the web. These APIs are often not well-known or properly documented, making it challenging for developers to fully utilize the available resources and functionalities.
To address this problem, our project offers developers a simple and hassle-free way to locate these hidden gems of APIs. We want to give developers access to a wide range of APIs that they might have otherwise missed out on. By making the API discovery process easier, we eliminate the need for developers to spend excessive time and effort searching for valuable APIs.
Solving the API discoverability issue brings significant benefits to developers. It saves them valuable time and effort, allowing them to focus on their core development tasks. With our project, developers can explore and utilize various APIs more easily, boosting their productivity and enabling them to create innovative applications more efficiently. In essence, our project empowers developers to bring their ideas to life by providing a streamlined approach to discovering and leveraging the validated APIs, opening up new possibilities for their projects.
The TLDR; Our end goal is to give developers a quick and easy way to locate APIs from lesser-known sources across the web.
Introduction🔥
On June 1st, Google Summer of Code (GSoC) officially started its coding phase, and I've already started working on it. First of all, I feel extremely fortunate to have been able to dive into open-source programming and make valuable contributions to a meaningful project thanks to the Google Summer of Code (GSoC) program and my organization, Postman. As my GSoC project begins to develop. I have come to an important stage where I need to establish a strong foundation organization program for my project. In this blog post, I'll discuss my experiences and learnings as I conclude my project's tech stack and draw up a detailed software architecture diagram.
Let's dive more into it, Shall we?
The Team Behind the Project 👥
Mr. Vinit Shahdeo - Mentor
Mr. Himanshu Sharma - Mentor
Mr. Mike Ralphson - Mentor
Mr. Harshil Jain - Mentor
Priyanshu Sharma - Mentee
Progress Made 🚀
In the initial week of GSoC, I made good progress in my project and reached significant milestones. It was a thrilling beginning as I successfully finalized my tech stack and created a visual representation of the project's flow using an architecture diagram. I'm excited about the achievements I've made so far and look forward to the journey ahead.
Tech Stack 💻
Frontend:
Next.js
Typescript
CSS3
Backend:
MongoDB
Elasticsearch with the ELK Stack (Elasticsearch, Logstash, and Kibana)
Sails.js
Web Crawling and Data Extraction:
cheerio
Kitebuilder
Validation and Data Processing:
- Swagger/OpenAPI Validator
Additional Tools and Data Sets:
Common Crawl
Assetnote 2020/21 Web Crawl Data set
Deployment and Infrastructure:
Docker
AWS
By using this tech stack, we can create a dynamic and robust web application. The frontend, powered by Next.js, will provide a seamless user experience with fast page rendering and smooth navigation. The combination of MongoDB and Elasticsearch with the ELK Stack will enable efficient data storage, retrieval, and search capabilities on the backend. Node.js with Sails.js will handle server-side logic and API integrations, ensuring a scalable and responsive application.
The web crawling and data extraction tools, such as cheerio and Kitebuilder, will allow us to gather data from various sources and extract relevant information. With the Swagger/OpenAPI Validator, we can ensure the validation and processing of incoming data. Additionally, the integration of datasets like Common Crawl and Assetnote 2020/21 Web Crawl Data set will provide access to extensive pre-existing information.
The application developed with this tech stack can be utilized for a wide range of purposes, such as content aggregation, data analysis, search engines, recommendation systems, and more. It offers the ability to handle large volumes of data efficiently and provides users with valuable insights and personalized experiences. Overall, this tech stack empowers the creation of a scalable, performant, and data-driven web application.
Software Architecture Diagram 🏗️
NOTE: Dotted lines represent bidirectional operations, while solid lines represent single direction operations.
We will be utilizing C4 diagrams to represent the architecture of our project in a simple and understandable way. C4 diagrams provide a clear visual representation of the system's key components, their relationships, and how they interact with each other. These diagrams use a set of standardized symbols and notations, making it easier for everyone involved to grasp the overall structure and design. By using C4 diagrams, we can communicate the project's architecture more effectively, facilitating better collaboration and understanding among team members and stakeholders.
Now, let's dive into the Architecture diagram, which provides a high-level view of our system.
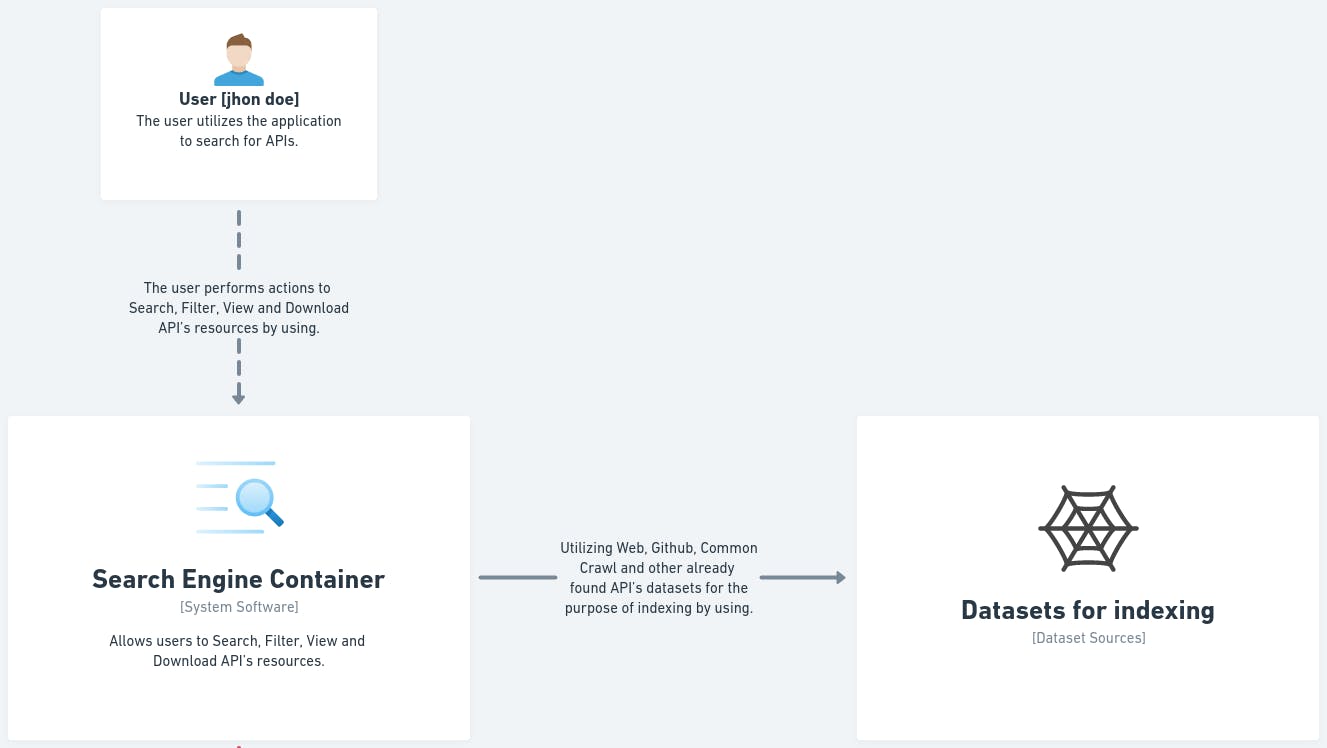
we start with the system Context Diagram, which represents the system's interactions with external entities, In the center, we have a search engine container, surrounded by two external entities, the User and the Dataset.
The search engine container allows users to Search, Filter, View, and Download API resources that are utilized by the user for example [jhon doe].
And, we have a Dataset that is utilized by search engine containers, the dataset contains API resources for the purpose of indexing.
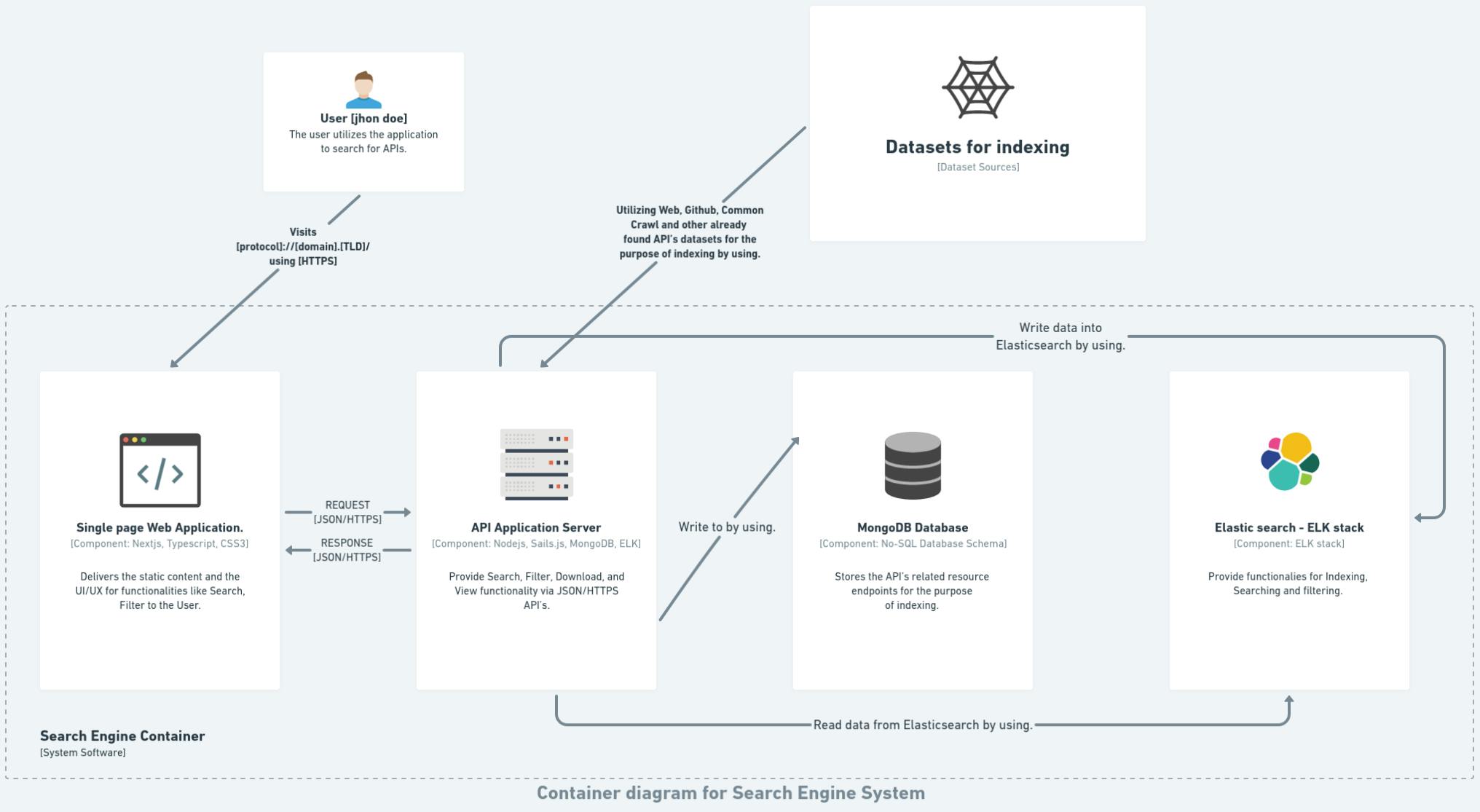
Following on, we have a search container diagram made of four parts, The Web UI, Application server, MongoDB database, and Elasticsearch DB.
The user utilizes the web application, which sends a GET request to the server. The server then responds with the appropriate response. In addition, the application server writes data to the MongoDB database, indexes the data in Elasticsearch, and searches for a query in Elasticsearch.
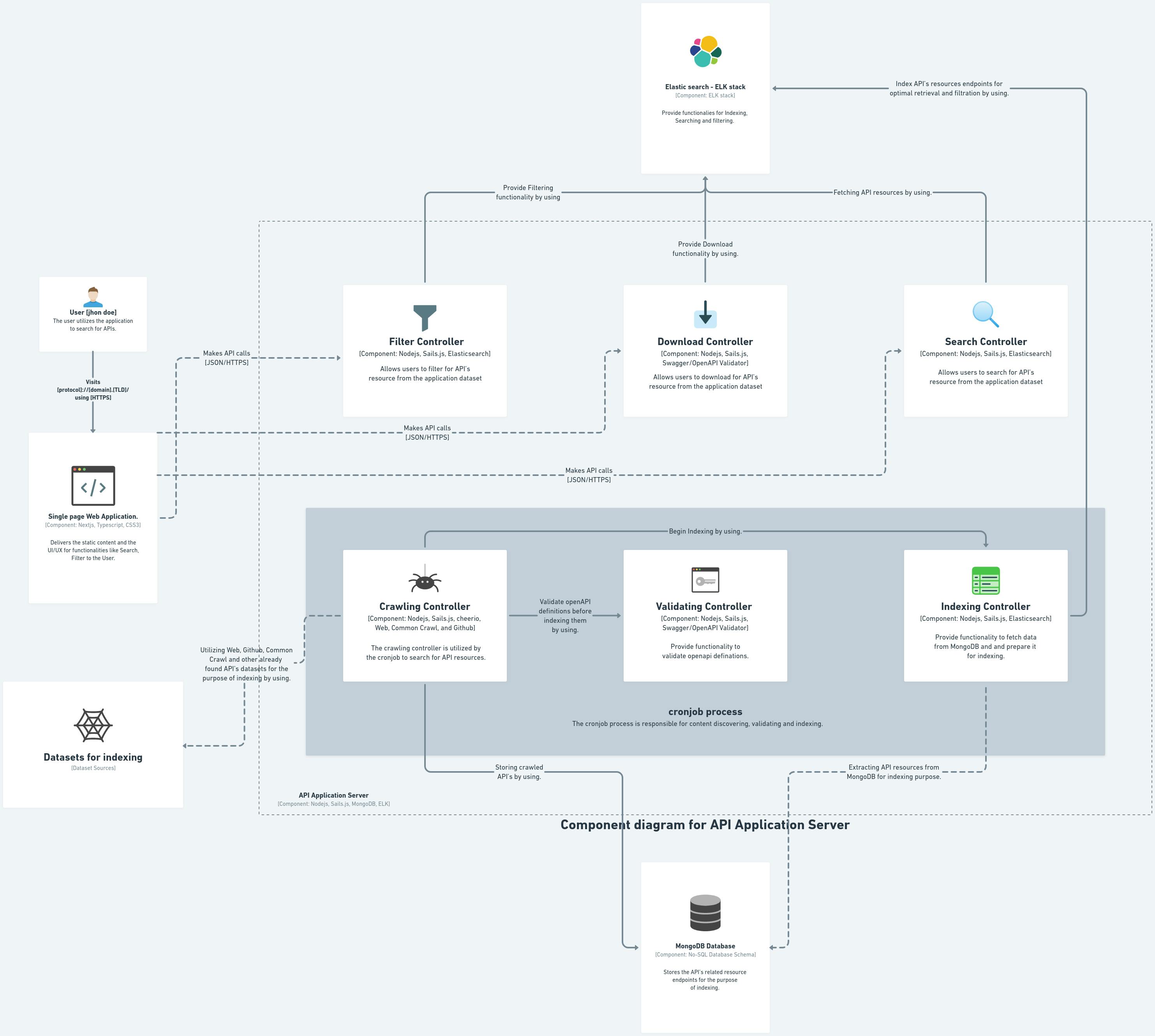
In the final part, we have the server component, which consists of six parts. The top three parts are directly used by the user, while the bottom three parts are background processes executed by the cronjob. The cronjob runs these processes once a week. The real essence of the project lies in the crawling, verification, and indexing processes. Now let me explain in detail.
First, we have the crawling controller, which has three jobs. Its first task is to extract data from the OpenAPI dataset. The second job is to validate the extracted data before indexing it. Finally, the crawling controller stores the validated data in the MongoDB database.
These tasks are completed sequentially by the crawling component**.**
The crawling aspect may be a little unclear, and I could have explained it better. That's why I made the data flow diagram thing, so you could see the crawling controller better.
Crawling datasets for API definitions -> Validating the crawled API definitions -> Storing the API definitions in MongoDB -> Finally Indexing the OpenAPI definitions in Elasticsearch by using MongoDB for optimal retrieval.
We plan to build all components in a way that, if required, they could be consumed independently, and validate controller is one of them. It is used by the crawling controller to ensure the data is valid. Lastly, the indexing controller has one important task. It extracts data from MongoDB and indexes it in Elasticsearch, which allows for efficient retrieval of the indexed data. These three controllers are initiated and utilized by a cronjob, as shown in the gray area. The cronjob runs the controllers sequentially once a week, ensuring regular execution of these processes.
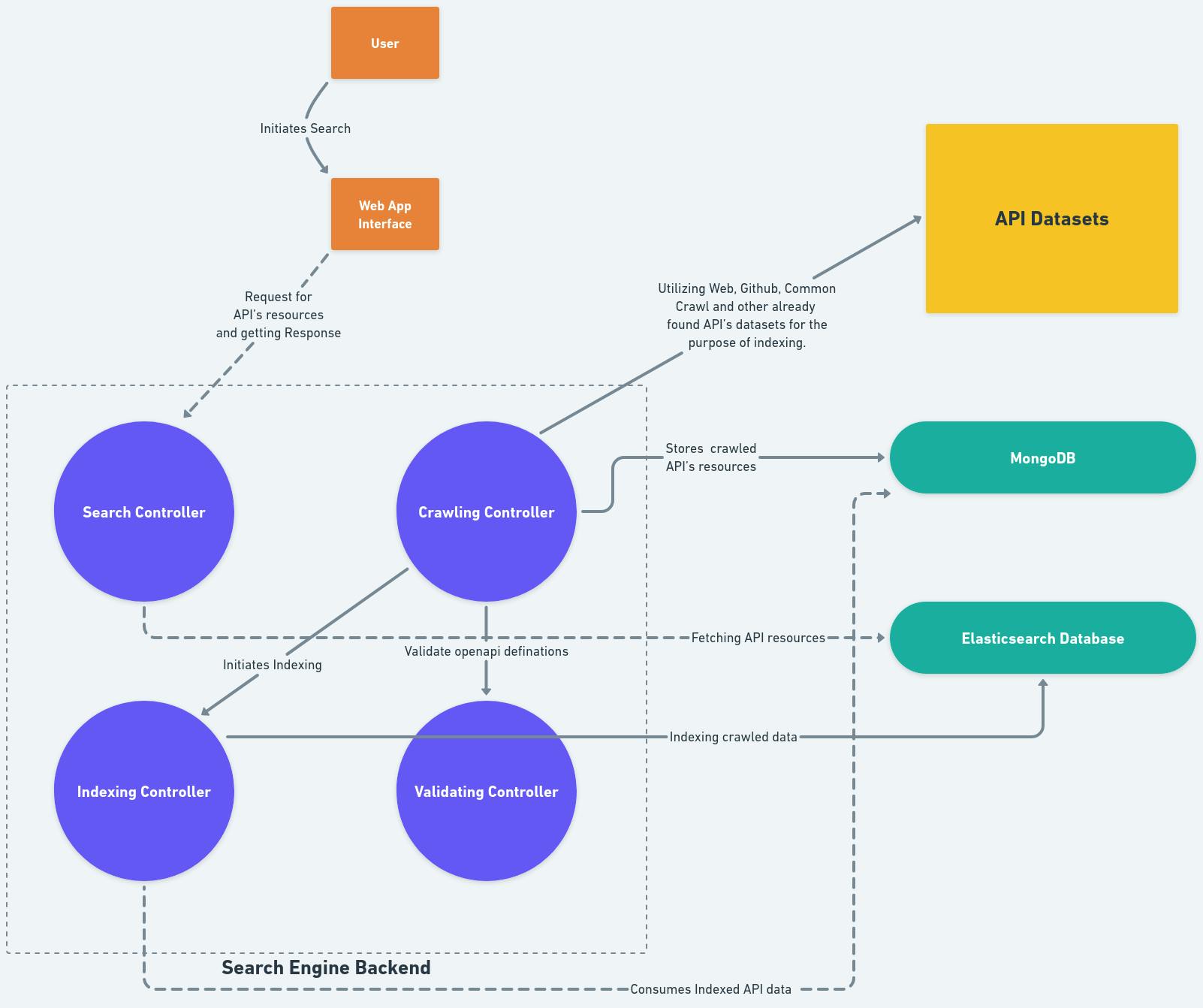
This is a higher-level representation of the diagram mentioned earlier. It provides an overview of the system's architecture, but it doesn't introduce any new information beyond what was explained before. This diagram is designed to be self-explanatory and serves as a summary of the previously discussed components and their interactions.
Conclusion 🔚
Understanding/Identifying the problem and finding or defining the solution is the first main step. In this blog post, I'll be sharing my experiences and thoughts during these stages. I hope to inspire and help other GSoC participants and developers with their own projects. This post is a significant milestone in my GSoC journey as it sets the groundwork for the upcoming implementation and development phases. Keep an eye out for more updates as my project moves forward!
Stay tuned for more updates on the progress of my GSoC project in the upcoming weeks! 🚀
Thank you for reading 🙏